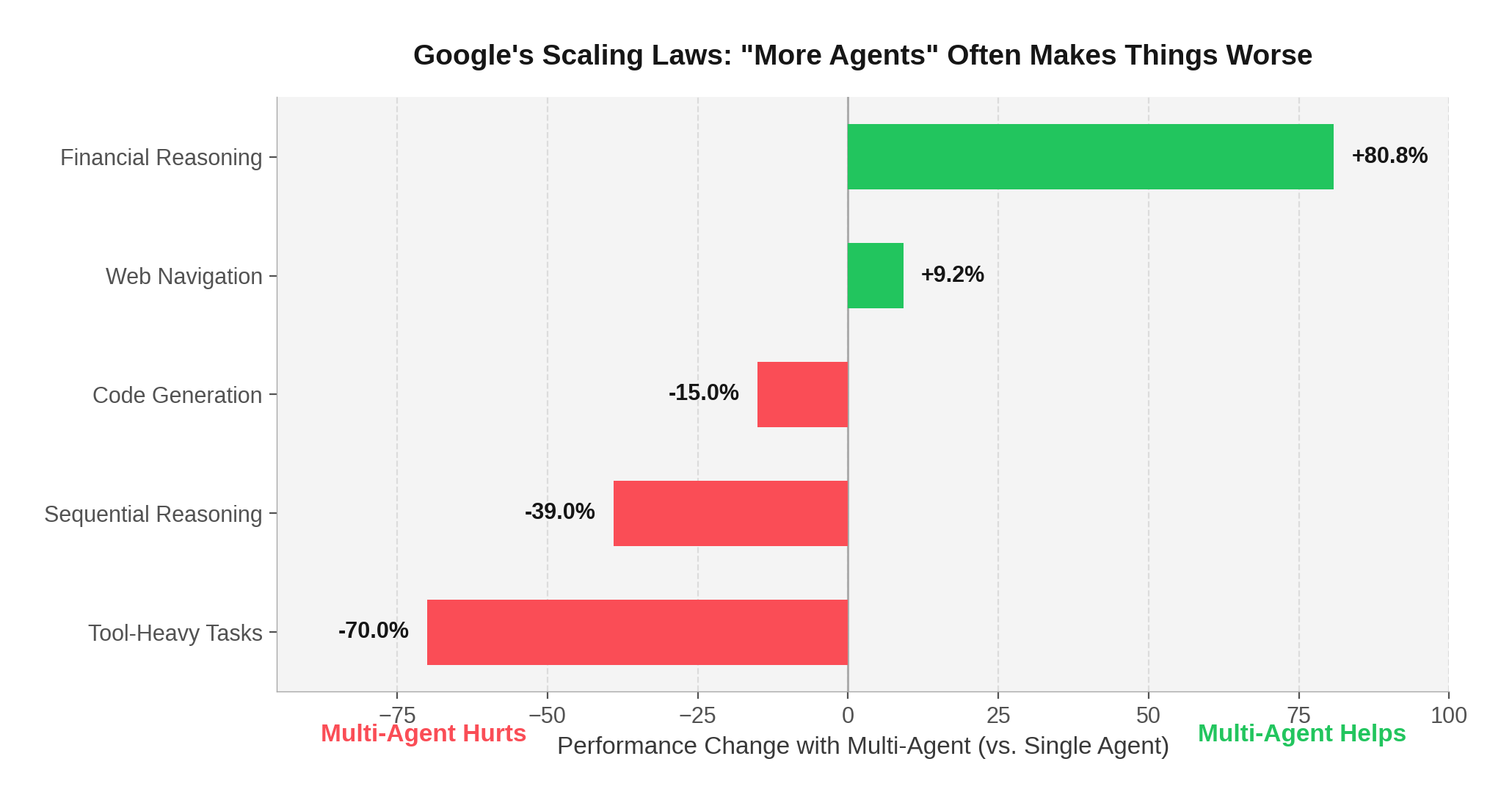
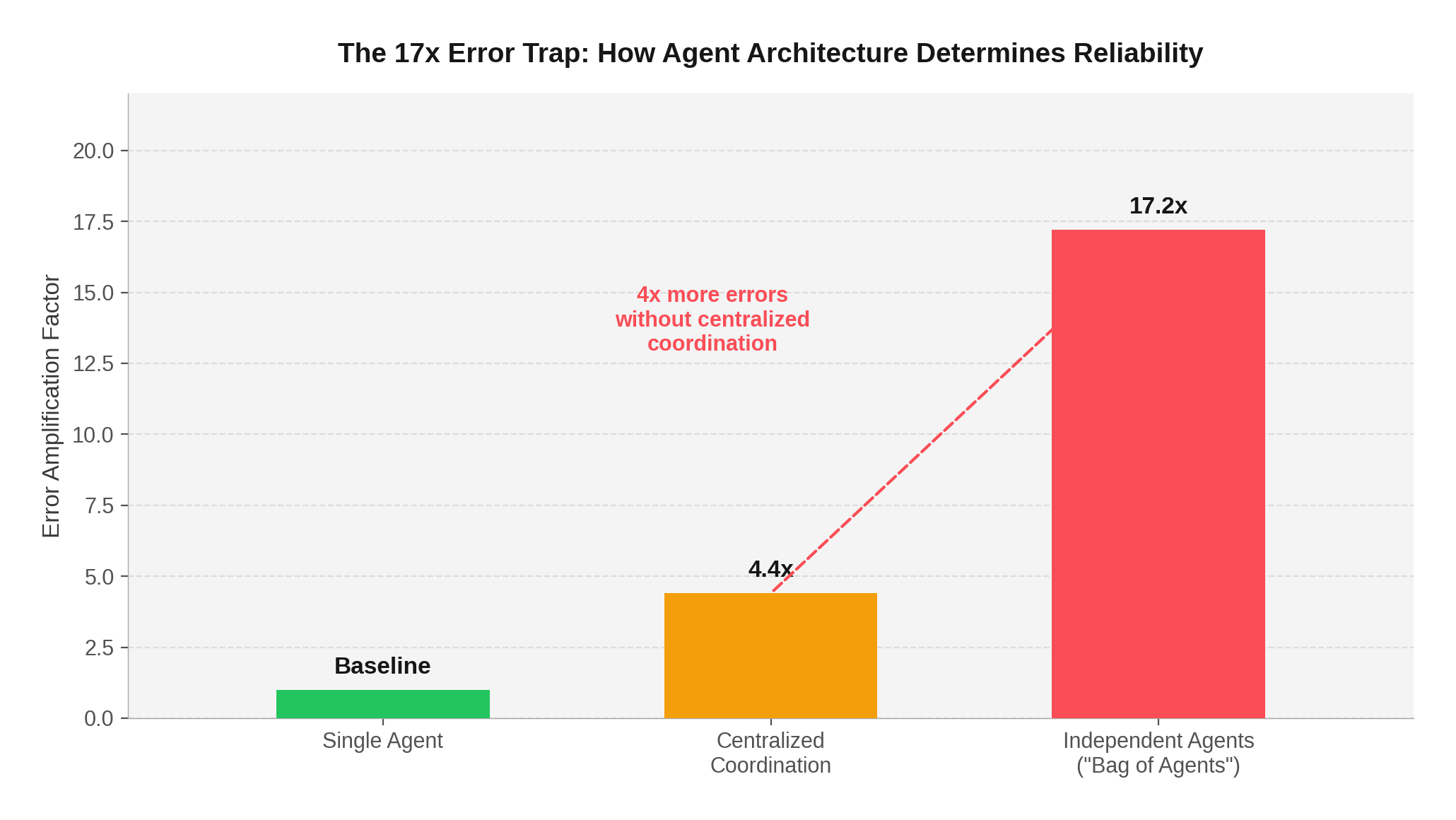
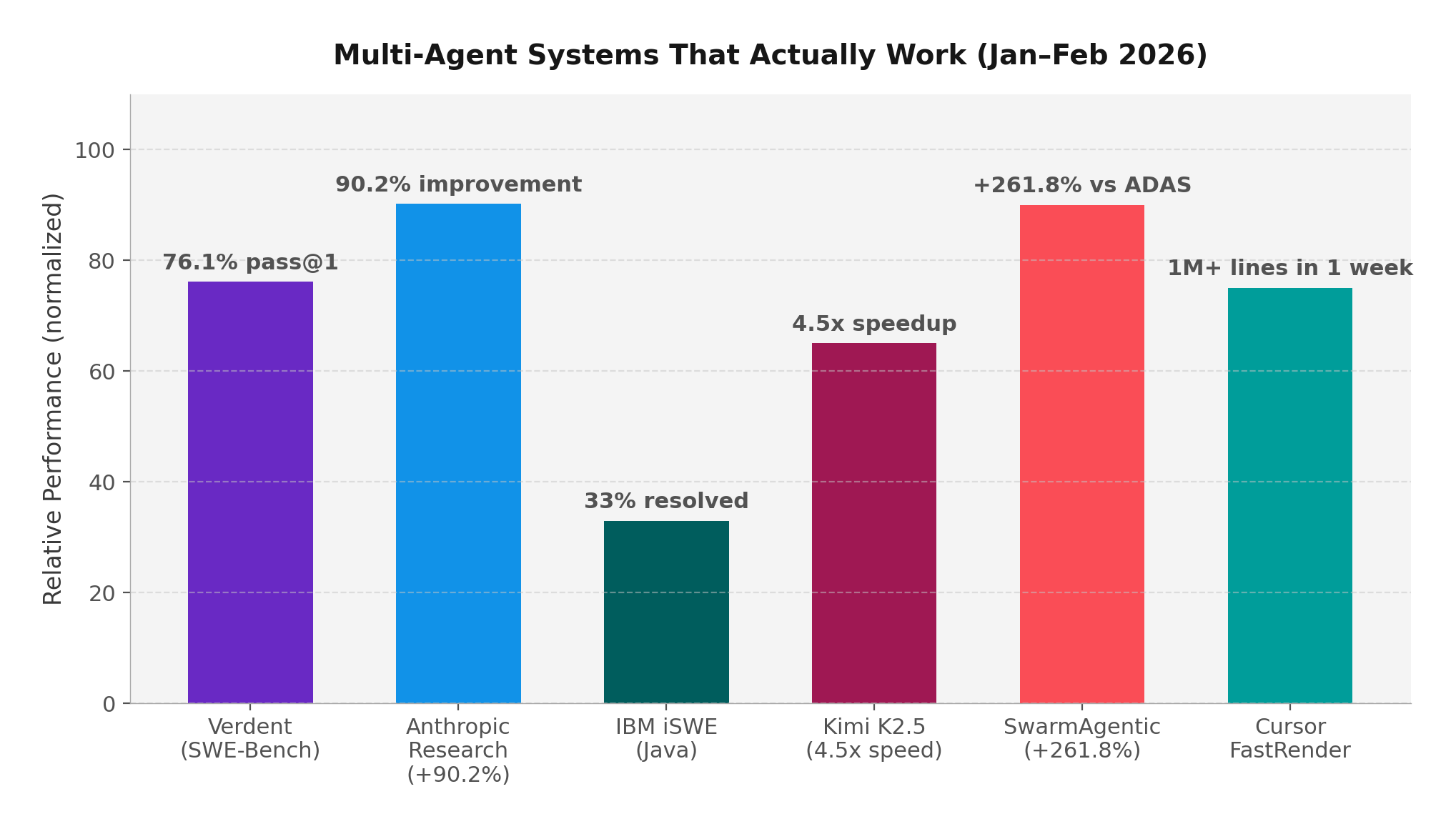
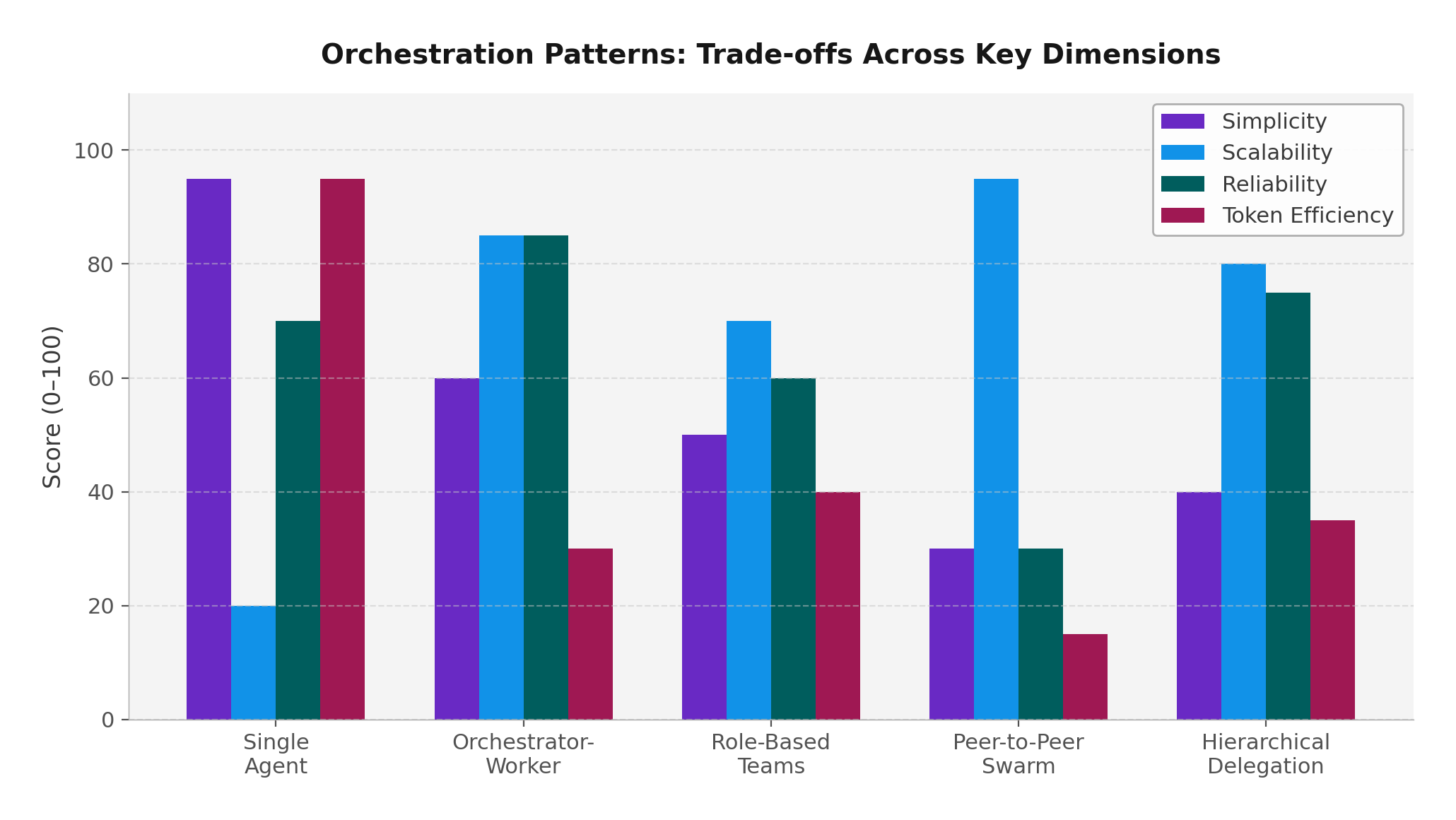
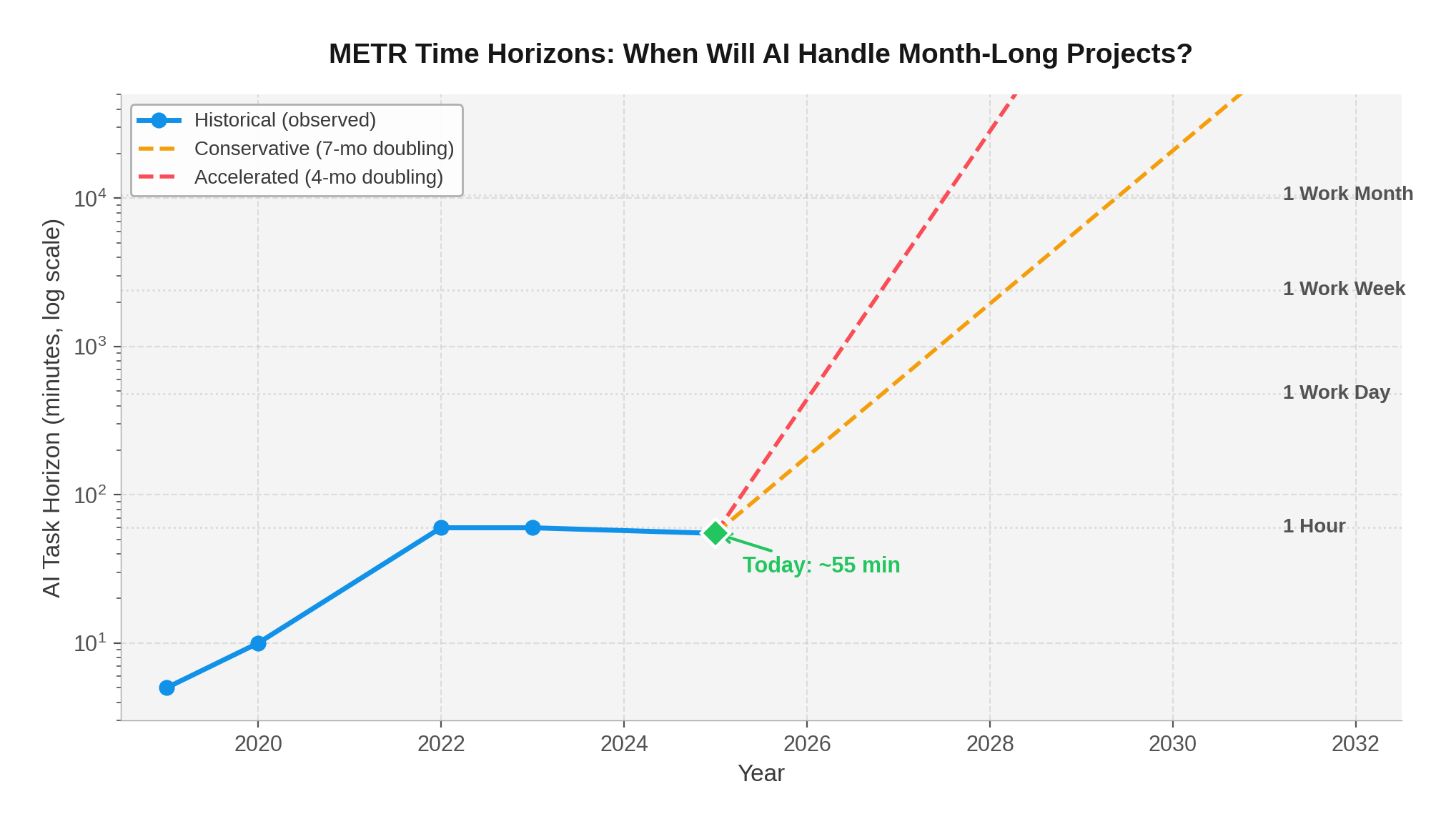
The 7.5% Reality Check
In January 2026, the multi-agent AI coding movement hit a wall of data. While SWE-Bench Verified scores climbed past 70% — fueling headlines about AI agents that can "solve real bugs" — a quieter set of benchmarks told a very different story.
ACE-Bench, presented at ICLR 2026, tested agents on what developers actually do: build complete features across multiple files, with tests, documentation, and integration. The result? Claude Sonnet 4 with OpenHands — the same system scoring 70.4% on SWE-Bench — achieved just 7.5% on ACE-Bench.
That's not a typo. A 10x performance drop when moving from isolated bug fixes to end-to-end feature development.
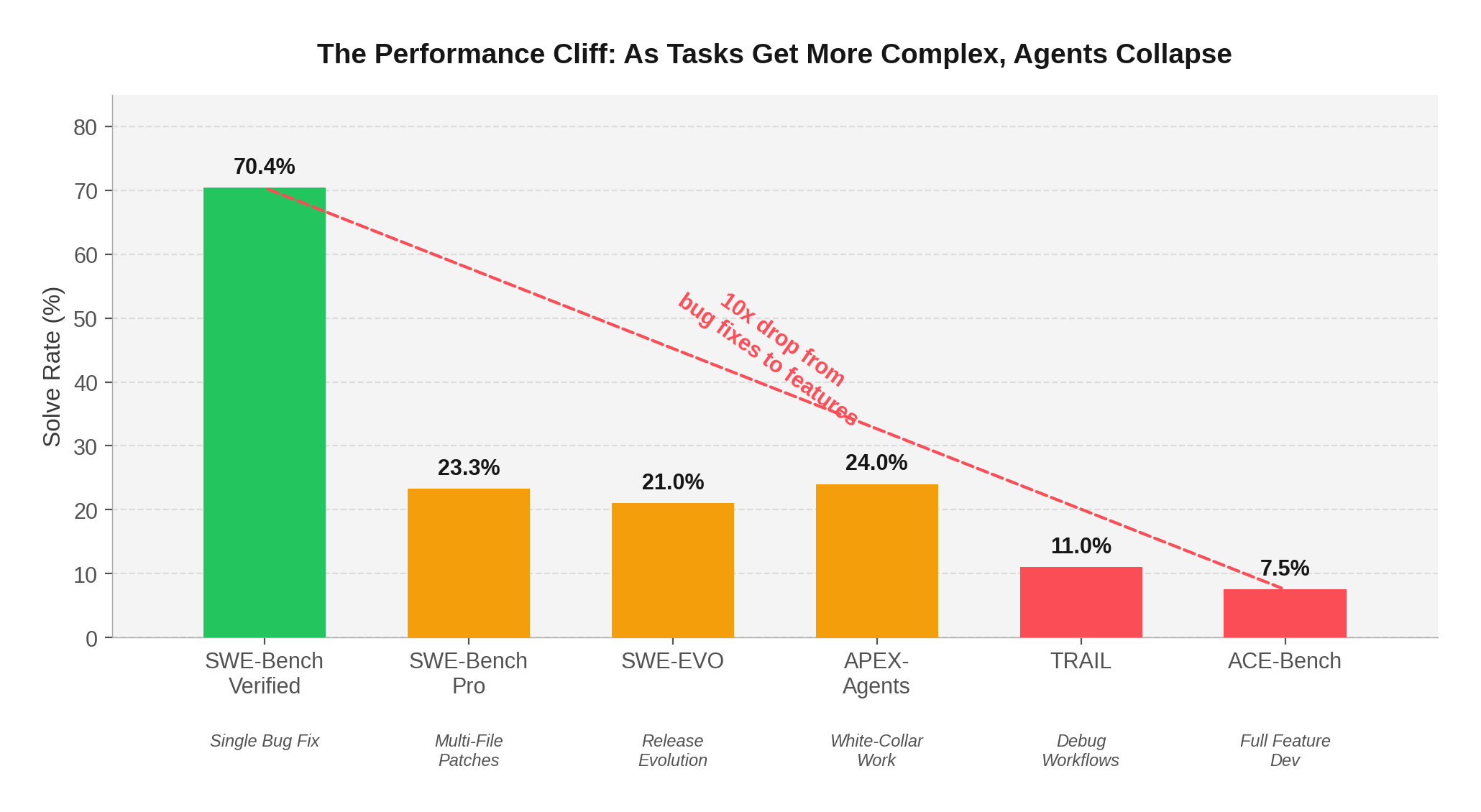
The pattern is consistent across every new benchmark released in the past three months:
SWE-EVO tested agents on release-note-driven evolution — evolving a codebase across an average of 21 files per task. GPT-5 scored 21%, down from 65% on SWE-Bench Verified. TRAIL from Patronus AI asked models to debug agent workflows themselves: Gemini 2.5 Pro achieved just 11% joint accuracy. APEX-Agents measured white-collar work tasks (consulting, investment banking, law) and the best model, Gemini 3 Flash, scored 24%.
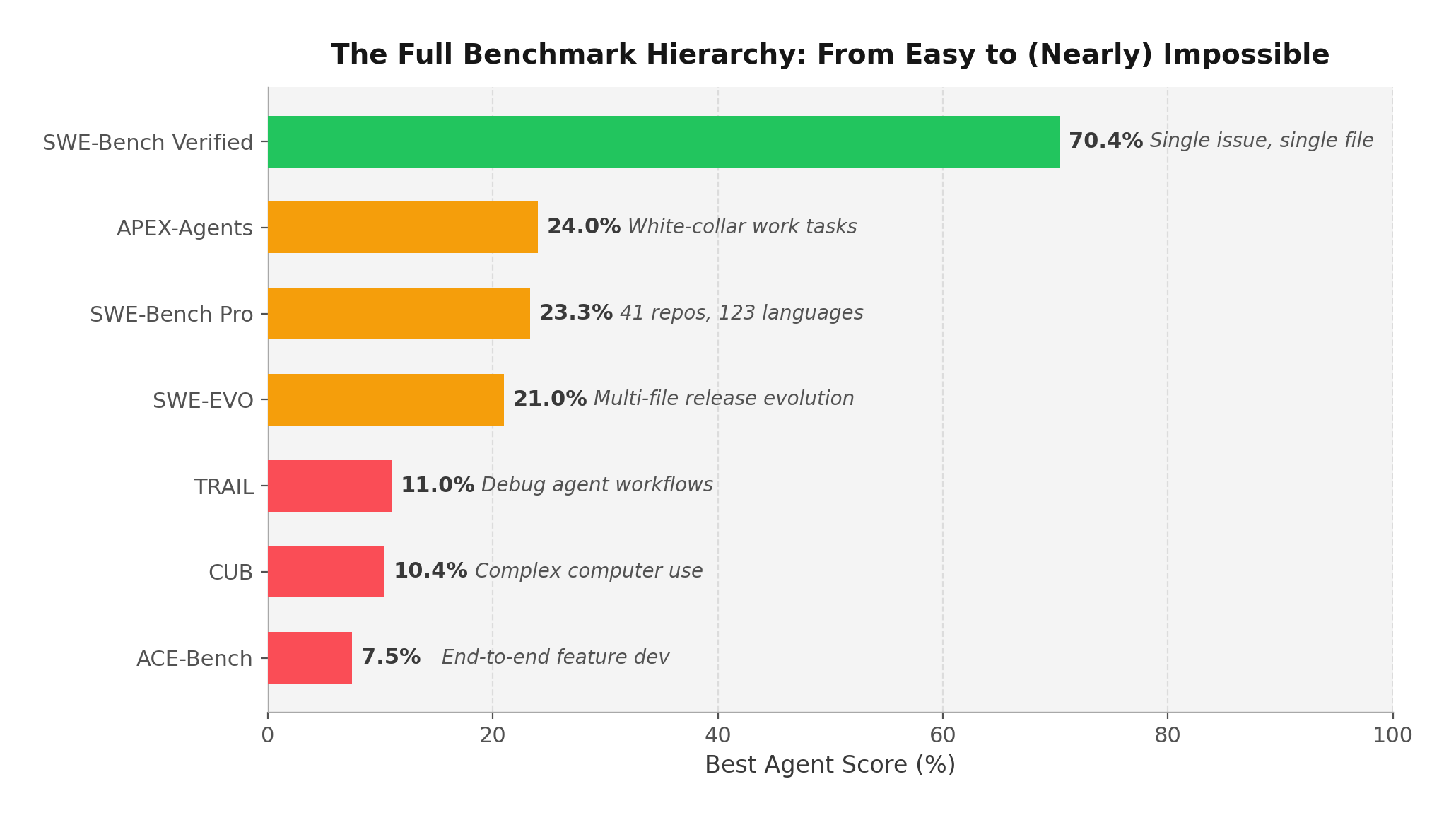
The Bottom Line
If your AI coding strategy is built on SWE-Bench scores, you're optimizing for the easiest 20% of real software engineering work. The benchmarks that matter — long-horizon evolution, cross-file features, multi-domain reasoning — show agents succeeding less than 25% of the time.